使用CNN进行模式识别(分类)代码(Python版)
最后更新于:2024-04-23 00:33:31
-CNN分类使用pytorch框架的快速实现
–支持一维、二维、三维数据,且有演示案例。
-可以自由设置神经网络卷积层结构、池化层结构
-可以快速划分训练集、验证集、测试集,程序运行完后绘制出测试集混淆矩阵
–多种训练参数可设置,包括迭代次数、初始学习率等等
-可设置随机种子,保证每次运行结果保持一致
–需要你做的基本只有导入数据和调参。
–绝大多数流程都被封装固化到函数中,仿照案例导入你的数据即刻得到结果~
一、代码运行环境
运行环境推荐为:VSCode+Anaconda+Pytorch+CUDA,配置教程见此处。
如果按照上述环境配置,则代码基本可以下载即用。
如果使用你的现有环境,需要安装依赖的包,这个可以根据代码运行时的报错内容判断和安装。
建议大家使用推荐环境。
二、程序介绍
程序文件
1.demoCNN_mnist.py
使用MNIST数据集进行手写字体数字的识别的案例,其中演示了FunClassCNNs函数对于二维数据(或者说黑白图片)的应用方式示范。
文件可以直接运行。程序运行完成后,将会画出如下图像:
(1)混淆矩阵图片。
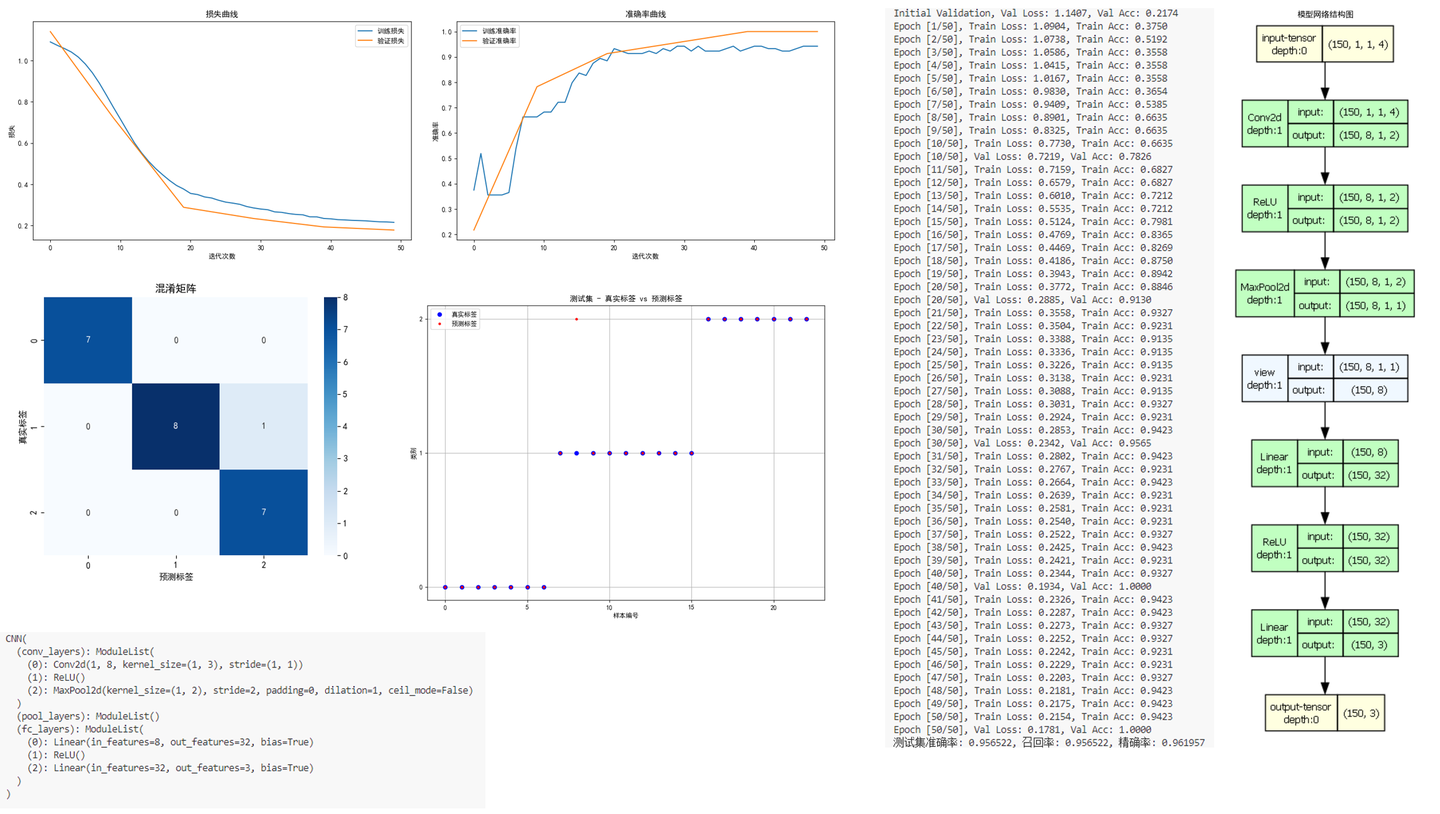
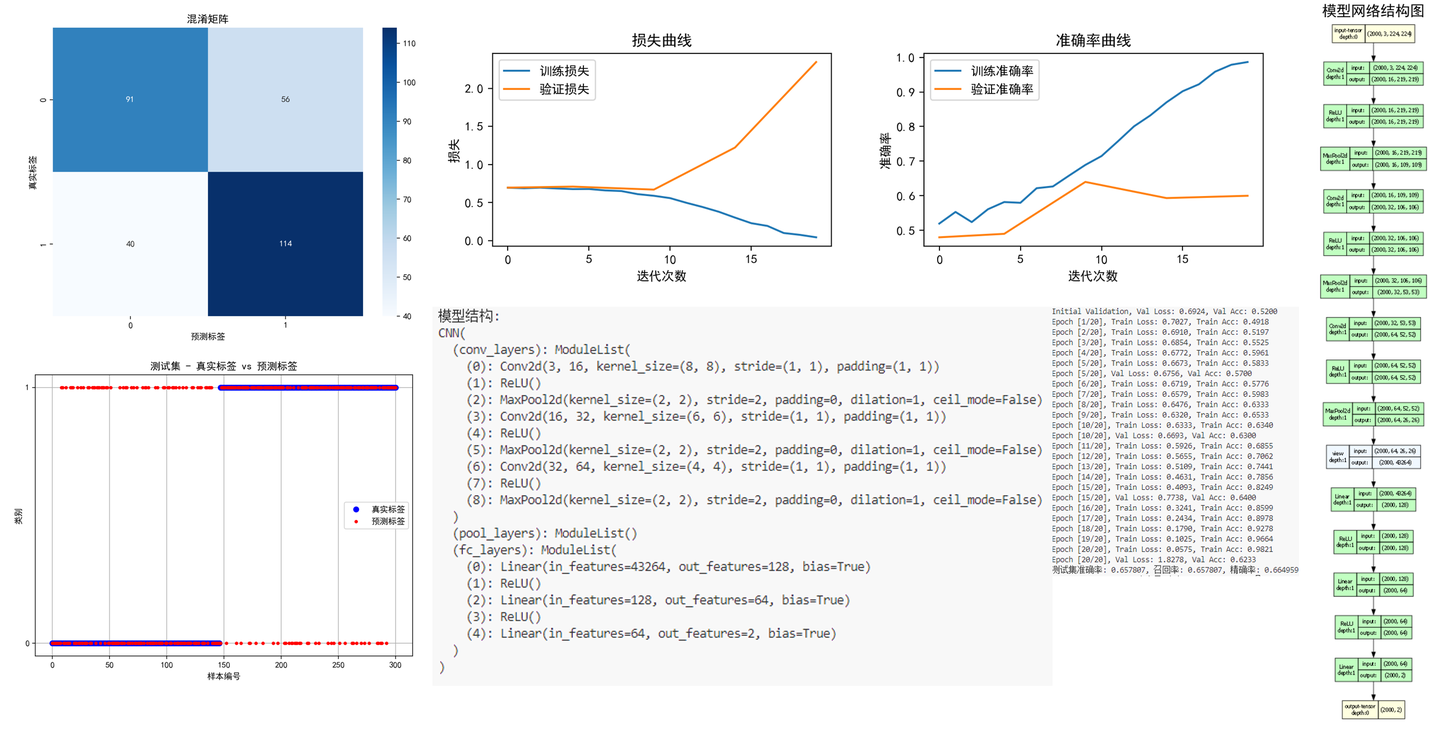
混淆矩阵(Confusion Matrix)是一种常用的评估分类模型性能的工具。就像下图,结果是一个正方形矩阵。其中每一行对应一个实际类别,每一列对应一个预测类别。对角线部分代表预测结果与实际类别相同(即预测正确)的数量,其余部分则代表预测错误的数量。
比如第3行第4列方框中的数字3,代表对于本次分类,有3个手写数字“3”被错误分类成了“2”。
解读混淆矩阵的关键是观察对角线元素和非对角线元素。在对角线上的元素表示正确分类的样本数量,而非对角线上的元素表示被误分类的样本数量。
需要注意的是,这个图针对的是测试集数据。
混淆矩阵可以全面地描述分类网络的特性,属于写论文必备图片。

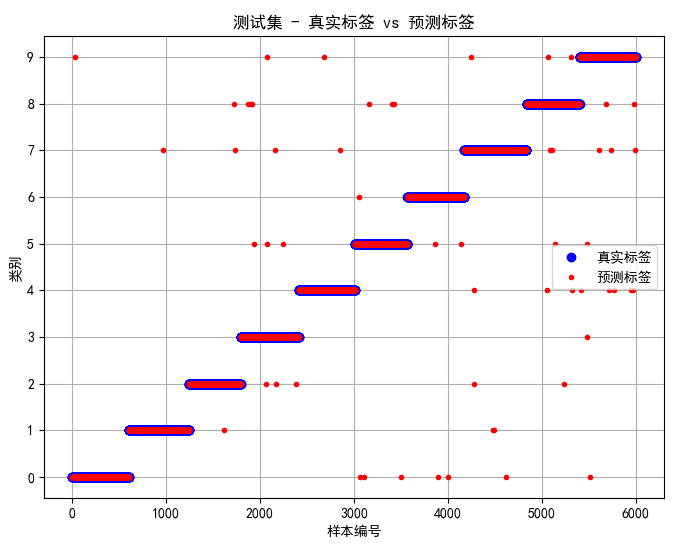
下边这张图可以反应预测标签被错误分类的整体态势,图中蓝色点是真实标签,红色标签是预测标签。完美情况是预测标签与真实标签完全重合,如果有被错误分类的情况,就会像下图这样出现很多散点。这张图现在在论文中也比较常见。
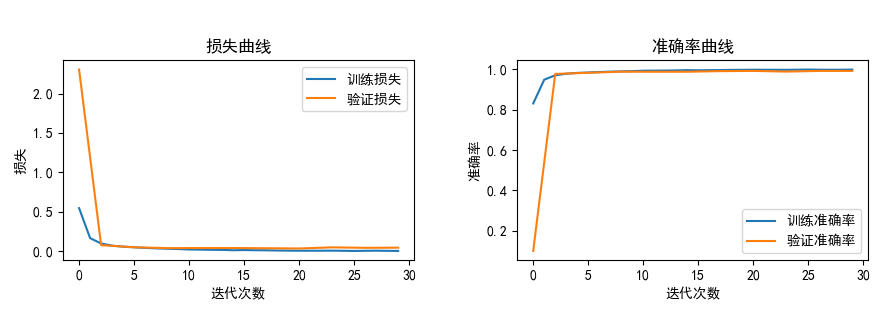
(2)训练过程图。
下边两张图分别是loss值和分类准确度的收敛过程。其中蓝色线条是训练集结果,橙色线条是验证集结果。
此图也是论文必画图之一。
(3)网络结构图、表。(完整版独有)
网络结构图中有每层网络的类型、输入和输出数据尺寸、网络结构等信息,方便大家论文中使用。

网络结构表中有网络中各个层的类型以及尺寸等信息,写论文时也用得到。

(4)训练过程表。
在模型的训练过程中,将在终端打印出训练集和测试集的实时Loss值和准确率值,就像下边这样:
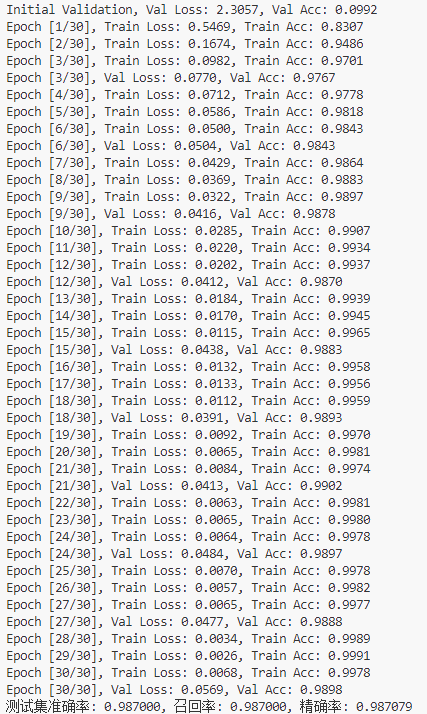
上边这个MNIST数据集测试集正确率是98.7%,这个是随意调了调网络和参数的结果,如果花时间进一步优化网络,可以得到更好的结果。
2.demoCNN_iris.py文件(完整版代码独有)
使用iris数据集进行鸢尾花数据集的识别的案例,其中演示了FunClassCNNs函数对于一维数据的应用方式示范。在这个例子里我们还演示了当数据文件为表格(CSV)时的处理方法。

鸢尾花
文件可以直接运行。程序运行完成后,将会画出如下图像(这些图像的含义与上边第一个案例相同):
3.demoCNN_catdog.py文件(完整版代码独有)
猫狗大战数据集中包含了不同尺寸的猫、狗彩色图像。
类别只有猫和狗两类。

本案例中为了轻量化程序文件,从其中选取了2000张图片(猫、狗各1000)。
文件可以直接运行。程序运行完成后,将会画出如下图像(这些图像的含义与上边第一个案例相同):
4.khCNN.py文件
使用CNN进行模式识别(分类)的快速实现的库文件,其中包含了FunClassCNNs函数,该函数的说明如下:
def FunClassCNNs(dataX, dataY, divideR, cLayer, poolingLayer, fcLayer, options, setting):
"""
使用CNN进行模式识别(分类)的快速实现函数,程序会优先使用GPU进行加速,如果没有GPU则使用CPU
参数:
- dataX: 输入数据,形状为(num_samples, num_channels, height, width)的numpy数组
- dataY: 标签值,形状为(num_samples,)的numpy数组,可以是向量型或索引型
- divideR: 数据集划分比例,形如[train_ratio, val_ratio, test_ratio]的列表
- cLayer: 卷积层结构,形状为(num_conv_layers, 5)的numpy数组,每一行代表一个卷积层的参数[filter_height, filter_width, num_filters, stride, padding]
- poolingLayer: 池化层结构,形状为(num_conv_layers, 5)的列表,每一行代表一个池化层的参数['pool_type', pool_height, pool_width, stride, padding],其中pool_type可以是'maxPooling2dLayer'或'averagePooling2dLayer'或'none'
- fcLayer: 全连接层结构,形状为(num_fc_layers,)的列表,每一个元素代表一个全连接层的输出维度,如果为空列表则只有一个输出维度等于类别数的全连接层
- options: 网络训练相关的选项,字典类型,包含以下键值对:
- 'solverName': 优化器类型,可以是'sgdm'或'rmsprop'或'adam',默认为'adam'
- 'MaxEpochs': 最大迭代次数,默认为30
- 'MiniBatchSize': 批量大小,默认为128
- 'InitialLearnRate': 初始学习率,默认为0.005
- 'ValidationFrequency': 验证频率,即每多少次迭代进行一次验证,默认为50
- 'LearnRateSchedule': 学习率调度方式,可以是'piecewise'或'none',默认为'none'
- 'LearnRateDropPeriod': 学习率下降周期,默认为10
- 'LearnRateDropFactor': 学习率下降因子,默认为0.95
- setting: 其他选项,字典类型,包含以下键值对:
- figflag: 是否绘制图像,'on'为绘制,'off'为不绘制
- deviceSel: 训练设备选择,可以是'cpu'或'gpu',默认为'gpu',当设置为'gpu'时,如果gpu硬件不可用,则会自动切换到cpu
- seed: 随机种子,整数,设置为0时不启用,设置为其他整数时启用,不同的整数为不同的种子值,变换种子值会影响结果,相同种子的计算结果是一致的,缺省时为不设置随机种子
- minmax: 是否进行归一化,布尔值,默认为True
返回值:
- accuracy: 测试集上的准确率
- recall: 测试集上的召回率
- precision: 测试集上的精确率
- model: 训练好的PyTorch模型
- info: 包含训练过程中的损失和准确率信息的字典
"""5.mnist.npz文件
mnist手写数字数据集文件,在程序中调用。
6.iris.csv文件
鸢尾花数据集文件,在程序中调用。
7.catdogFig文件夹
猫、狗图片存放的文件夹。
8.torchview文件夹
绘制网络结构图依赖的文件。
三、快速开始
1.环境配置
1.1 运行环境推荐为:VSCode+Anaconda+Pytorch+CUDA,配置教程见此处。
1.2 在配置好上述环境后,还需要安装以下包:
pip install graphviz1.3 另外,为了正确绘制混淆矩阵图,需要执行以下代码实现matplotlib的降级。
conda install matplotlib=3.7.21.4 点击这个链接,下载graphviz的安装包。
运行安装包,点击下一步。
点击接受。
注意!这步要选第二项:Add Graphviz to the system PATH for all users
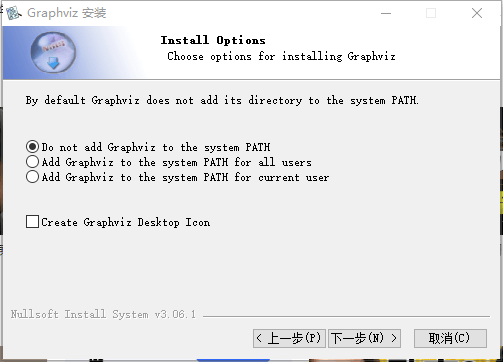
选择一个路径进行安装。
安装完之后重启电脑。
至此环境配置完成。
2.运行测试脚本
先在vscode里打开下载好的文件夹,然后运行demoCNN_iris.py程序,程序运行完毕后如果没报错,且正常画出上述图像,则说明运行环境正常,程序正确。
3.替换成你自己的数据
复制一个demoCNN_iris.py(或者根据需要复制demoCNN_catdog.py或demoCNN_iris.py)的文件副本,这些demo文件的第一节都是加载数据集,大家参考这几个demo文件中的第一节的数据导入方法,替换成你自己的数据。
不过需要提醒大家注意,数据导入后的变量名,输入数据请命名为xData,输出数据命名为yData。xData需要是numpy数组,且形状为(num_samples, num_channels, height, width),比如对于mnist数据集,其形状需要转化为60000*1*28*28,num_samples即数据组数,mnist是灰度图为单通道,所以num_channels为1,height和width是图片大小28*28像素。
四、关于完整版与公开版代码
| 功能 | 完整版 | 公开版 |
| 数据导入、参数设置、实现分类 | √ | √ |
| 软件全部源码(py文件) | √ | × |
| 混淆矩阵等图片无水印,可绘制网络结构图 | √ | × |
| 适用于的数据类型 | 一维、二维、三维 | 仅二维 |
| 最大迭代次数 | 不限制 | 5 |
| 最大卷积层层数 | 不限制 | 2 |
| 导出预测准确度、训练好的网络模型、神经网络训练相关参数(如loss值、准确度)等 | 可导出 | 不可导出 |
| CNN网络数据预处理、调参技巧视频教程 | √ | × |
五、获取公开版程序(需使用电脑浏览器打开)
CNN分类Python代码公开版
注:公开版代码需使用Python3.11版本的conda
六、获取完整版程序(使用电脑浏览器或者手机浏览器打开)
获取通道一(淘宝):点击此处获取完整版程序
获取通道二(本页面):点击下面“立即支付”按钮,付款后获取完整版代码下载链接和售后联系方式~本通道处于测试阶段,使用该通道可以额外优惠(仅需86.5元)。付款完成后刷新一下本页面即可看到下载链接。
(注意支付跳转失败的话,请使用浏览器打开本页面)
七、完整版代码重要更新
20240421 完成初版代码
八、常见问题
Q1:报错:DLL load failed while importing khCNN: 找不到指定的模块。
A1:原因是对于公开版代码,需要将当前的Python版本设定为3.11。使用以下步骤:
1.卸载你现在安装的anaconda,重启电脑。
2.点击这个链接,下载anaconda软件。然后参考这篇文章中的第三章和第四章配置环境。
Q2:绘制的混淆矩阵只有第一行有数字。
A2:这是由于matplotlib版本较高,导致API变化导致的。
在cmd执行这条指令:conda install matplotlib=3.7.2
实现matplotlib版本降级即可。