使用CNN进行模式识别(分类)代码
最后更新于:2024-04-21 22:54:24
-支持一维、二维、三维数据,且有演示案例。
-可以自由设置神经网络卷积层结构、池化层结构
-可以快速划分训练集、验证集、测试集,程序运行完后绘制出测试集混淆矩阵
-支持向量和索引两种形式的标签输入
-多种训练参数可设置,包括求解器、迭代次数、初始学习率等等
-可设置随机种子,保证每次运行结果保持一致
–需要你做的基本只有导入数据和调参。
–绝大多数流程都被封装固化到函数中,仿照案例导入你的数据即刻得到结果~
一、代码运行环境
MATLAB2018b及更新版本。
二、程序介绍
注: 图标代表该m文件为脚本文件,可以直接运行;
图标代表该m文件为脚本文件,可以直接运行; 图标代表函数文件,在没有输入变量的情况下无法直接运行。更详细的解释可以看这里。
图标代表函数文件,在没有输入变量的情况下无法直接运行。更详细的解释可以看这里。
1.scriptClassCNNs_MNIST.m文件
使用MNIST数据集进行手写字体数字的识别的案例,其中演示了FunClassCNNs函数对于二维数据(或者说黑白图片)的应用方式示范。
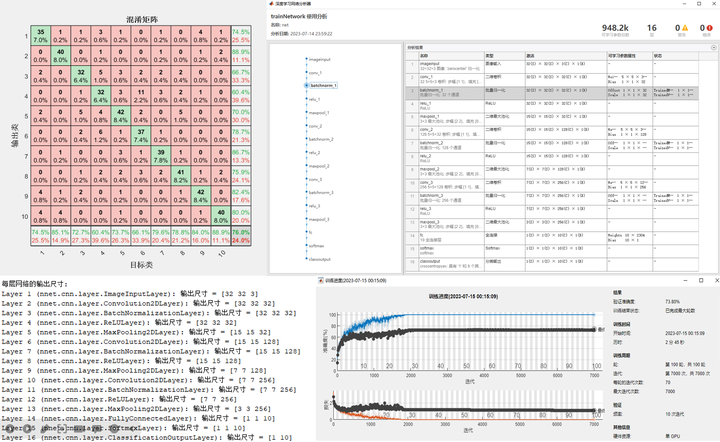
文件可以直接运行。程序运行完成后,将会画出如下图像:
(1)混淆矩阵图片。
混淆矩阵(Confusion Matrix)是一种常用的评估分类模型性能的工具。就像下图,结果是一个正方形矩阵。其中每一列对应一个实际类别,每一行对应一个预测类别。对角线绿色部分代表预测结果与实际类别相同(即预测正确)的数量和比例,红色部分则代表预测错误的数量和比例。
比如第3行第4列红色方框中的数字1,代表对于本次分类,有一个手写数字“3”被分类成了“2”。
解读混淆矩阵的关键是观察对角线元素和非对角线元素。在对角线上的元素表示正确分类的样本数量,而非对角线上的元素表示被误分类的样本数量。
最下边一行代表了“每类数据实际识别成功的比例”;最右边一列“分类为该类别的数据中实际属于该类别的比例”,稍微有点绕,大家可以多念几遍。。。
最右下角的数据及全体数据的识别准确率。
需要注意的是,这个图针对的是测试集数据。
混淆矩阵可以全面地描述分类网络的特性,属于写论文必备图片。
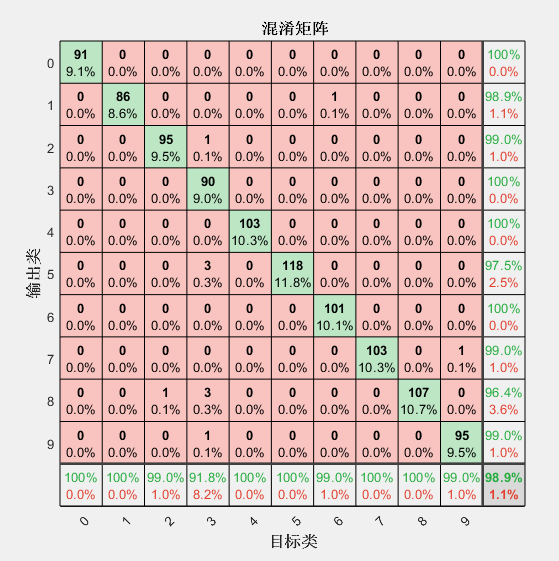
混淆矩阵
(2)训练过程图。
这张图片在程序运行的阶段就在不断更新迭代,上下两张图分别是分类准确度和loss值的收敛过程。其中蓝色线条是训练集结果,黑色线条是验证集结果。
如果嫌这张图丑的,同学们也可以用导出的训练过程数据自己画图,程序运行完之后,相关数据在MATLAB工作区的info变量里可以找到。
此图也是论文必画图之一。
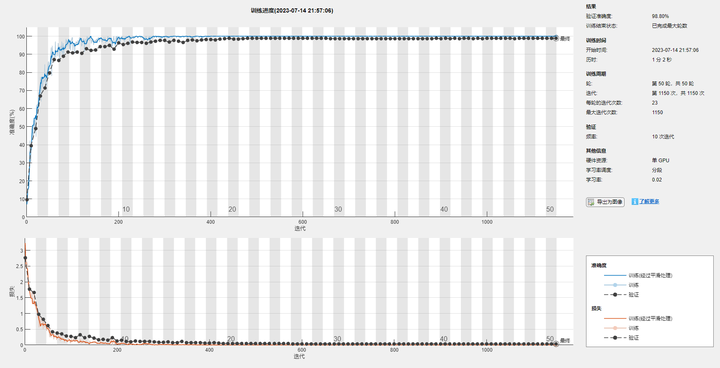
训练过程图
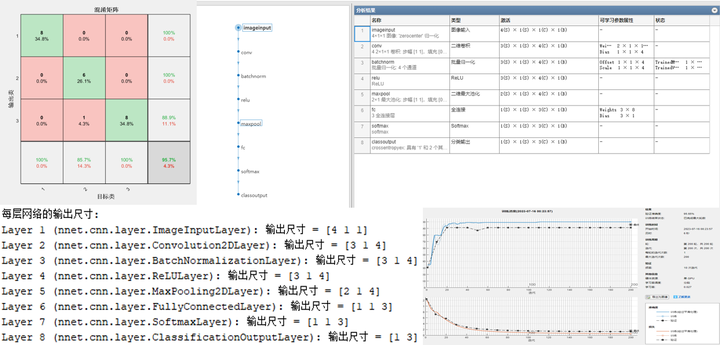
(3)网络结构图、表。
这张图包含了网络结构图,以及每层网络的名称、类型、参数属性等信息表格。方便大家论文中使用。

(4)每层网络的输出尺寸。
在做CNN网络结构设计的时候,随着层数的叠加,每个特征图的尺寸越来越小,有时候一不小心就会使特征图的尺寸变为负数,然后程序自然会报错。
为了解决这个问题,笔者特地加了一个功能,可以计算出数据经过每层网络之后输出的特征图的尺寸,就像下图这样:

该结果会在命令行窗口打印出来
在实际调试过程中,你会发现这个功能非常好用。
上边这个MNIST数据集测试集正确率是98.9%,这个是随意调了调网络和参数的结果,如果花时间进一步优化网络,可以得到更好的结果。
2.scriptClassCNNs_IRIS.m文件(完整版代码独有)
使用MNIST数据集进行鸢尾花数据集的识别的案例,其中演示了FunClassCNNs函数对于一维数据的应用方式示范。

鸢尾花
文件可以直接运行。程序运行完成后,将会画出如下图像(这些图像的含义与上边第一个案例相同):
3.scriptClassCNNs_IRIS.m文件(完整版代码独有)
使用MNIST数据集进行CIFAR-10数据集(32×32彩色图像)的识别的案例,其中演示了FunClassCNNs函数对于三维数据(或者彩色图像)的应用方式示范。

CIFAR-10数据集,10个类别分别抽取了10张图
文件可以直接运行。程序运行完成后,将会画出如下图像(这些图像的含义与上边第一个案例相同):
4.FunClassCNNs.m文件
使用CNN进行模式识别(分类)的快速实现函数。
function [accuracy,recall,precision,net,info] = FunClassCNNs(dataX,dataY,divideR,cLayer,poolingLayer,fcLayer,options,figflag)
% 使用CNN进行模式识别(分类)的快速实现函数
% 该函数需要输入的数据为array数组型,如果是图片数据则需要通过imread等方式进行读取转换
% 输入:
% dataX:输入数据,R1*R2*R3*Q的矩阵,Rn为输入数据的维度,Q为批次数,输入该变量时一定要注意维度正确
% 例1:对于3通道的图像数据,例如长28像素,宽28像素,共5000组数据,则dataX的维度为:28*28*3*5000
% 例2:对于一维数组,每组数据长度为20,共1000组数据,则dataX的可以维度为:1*20*1*1000或20*1*1*1000
% dataY:标签值,可以为两种方式:
% 向量型:U*Q的矩阵,U为标签种类数,Q为批次数
% 索引型:1*Q的矩阵,Q为批次数
% divideR:数据集(训练集、验证集、测试集)划分比例,如:divideR =[0.6,0.2,0.2],
% 则代表60%数据用于训练集,20%数据用于验证集,20%数据用于测试集
% cLayer:卷积层结构,为n*5的二维数组,其中n为卷积层的数量
% 列向的5个维度时分别代表滤波器的高、滤波器的宽、滤波器数量、步长、填充
% 例1,cLayer =
% [3,16,1,1;3,32,1,0]时,则代表有两层卷积层,其中第一层滤波器高为3,宽为3,滤波器数量为16,步长1,填充1
% 第二次滤波器高为3,宽为3,滤波器数量为32,步长1,填充0
% 例2,cLayer =
% [3,1,16,1,1;3,1,32,1,0]时,则代表有两层卷积层,其中第一层滤波器高为3,宽为1,滤波器数量为16,步长1,填充1
% 第二次滤波器高为3,宽为1,滤波器数量为32,步长1,填充0
% poolingLayer:池化层结构,为长度为n*5的cell数据,其中n为池化层的数量,和卷积层层数相同。
% 列向的三个维度分别代表:1.池化层类型,分为'maxPooling2dLayer'和'averagePooling2dLayer'两种,如果不用池化层设置为'none'
% 2.池化区域高度尺寸
% 3.池化区域宽度尺寸
% 4.步长
% 5.填充
% 例如:
% poolingLayer = {'maxPooling2dLayer',2,2,2,1; 'averagePooling2dLayer',2,2,1,0};
% 代表第一个池化层为最大池化层,尺寸为2*2,步长2,填充1,第二个池化层为平均池化层,尺寸为2*2,步长1,填充0
% 注意!如果对应卷积层后不设置池化层,请在对应的位置设置为'none',0,0,0,0
% 比如cLayer设置为两层时,如果只想在第一层卷积层后对应有池化层,第二层卷积层后无池化层,那么池化层应该设置为:
% poolingLayer = {'maxPooling2dLayer',1,2,1,0;
% 'none',0,0,0,0 }; %后边的四个0主要是占位,不起实际作用
% options:一些与网络训练等相关的设置,使用结构体方式赋值,比如 options.MaxEpochs = 1000,具体包括:
% solverName:求解器,'sgdm'(默认) | 'rmsprop' | 'adam'
% MaxEpochs:最大迭代次数,默认30
% MiniBatchSize:批尺寸,默认128
% GradientThreshold:梯度极限,默认为Inf
% InitialLearnRate:初始化学习速率(默认0.005)
% Plots:是否显示训练过程,'none' 为不显示(默认) | 'training-progress'为显示
% ValidationFrequency:验证频率,即每间隔多少次迭代进行一次验证,默认50
% LearnRateSchedule:即LearnRateSchedule是否在一定迭代次数后学习速率下降, LearnRateSchedule ='piecewise'为使用,'none'为不使用(默认)
% LearnRateDropPeriod:即LearnRateDropPeriod学习速率下降时的迭代数,默认为10
% LearnRateDropFactor:即LearnRateDropFactor学习速率下降因子,下降后变为LearnRateDropFactor*InitialLearnRate,LearnRateSchedule为0时可以赋0,默认为0.1
% (未启用)NorFlag:即Normalization Flag,设置为1时则在程序中进行数据归一化和反归一化操作,否则不进行,建议设置为1
% SeedFlag:随机种子标志,设置为1时启用随机种子,(默认为1)
% fcLayer:全连接层,可以设置多层,如果设置fcLayer=[],则在网络结构中只包含一个全连接层,输出的维度与数据类别相同。
% 如果设置fcLayer为数组,则代表在上边的全连接层之前再加入对应数量的全连接层和ReLU层
% 例如设置fcLayer=[32,16],则代表在共有三个全连接层,第一个是fullyConnectedLayer(32)+ReLU,第二个是fullyConnectedLayer(16)+ReLU,
% 第三个是fullyConnectedLayer(numClasses)
% figflag:是否画图,'on'为画图,'off'为不画
% 输出:
% accuracy:测试集分类正确率
% recall: 召回率
% precision: 精确率
% net:训练好的网络
% info:神经网络训练相关参数,如loss值、准确度等5.EvaluteClassResults.m文件
对分类结果进行评价,包括:画混淆矩阵图、recall、precision等
function [recall, precision] = EvaluteClassResults(outputs,targets,figflag)
% 对分类结果进行评价,包括:
% 画混淆矩阵图
% 计算 weigthed-Precision, weigthed-Recall和F1-score 参考 https://zhuanlan.zhihu.com/p/147663370?from_voters_page=true
% 输入:
% outputs:经过分类算法得到的分类结果,一维正整数
% targets:目标分类结果,一维正整数
% figflag:是否画图,'on'为画图,'off'为不画
% 输出:
% recall: 召回率
% precision: 精确率6.clcEvaluteCalss.m文件
计算recall、precision的底层代码。
function [recall, precision] = clcEvaluteCalss(outputs,targets)
% 计算 weigthed-Precision, weigthed-Recall 参考 https://zhuanlan.zhihu.com/p/147663370?from_voters_page=true
% 注意,outputs和targets中的分类为整型,从1排序到n,不可跳数三、快速开始
1.运行测试脚本
先在MATLAB里打开下载好的文件夹,然后运行scriptClassCNNs_MNIST.m程序,程序运行完毕后如果没报错,且正常画出上述图像,则说明运行环境正常,程序正确。
2.修改仿真数据/导入数据
复制一个scriptClassCNNs_MNIST.m(或者根据需要复制scriptClassCNNs_IRIS.m或scriptClassCNNs_CIFAR.m)的文件副本,在这个副本里做如下修改:
根据你的文件类型的不同(excel,txt,csv等),将数据导入MATLAB的方法有所不同。同学们可以看博主针对常用文件的导入方法的这个教程,教程上未包含的数据类型,大家可以再参考这个文档。
需要注意,导入的数据需要满足数据格式要求:
% dataX:输入数据,R1*R2*R3*Q的矩阵,Rn为输入数据的维度,Q为批次数,输入该变量时一定要注意维度正确
% 例1:对于3通道的图像数据,例如长28像素,宽28像素,共5000组数据,则dataX的维度为:28*28*3*5000
% 例2:对于一维数组,每组数据长度为20,共1000组数据,则dataX的可以维度为:1*20*1*1000或20*1*1*1000
% dataY:标签值,可以为两种方式:
% 向量型:U*Q的矩阵,U为标签种类数,Q为批次数
% 索引型:1*Q的矩阵,Q为批次数3.实现CNN分类
参照脚本文件中第二步,根据需要调整相关参数(购买完整版代码,可获取调参技巧教学视频)。
运行程序即可。
四、关于完整版与公开版代码
| 功能 | 完整版 | 公开版 |
| 数据导入、参数设置、实现分类 | √ | √ |
| 软件全部源码(函数m文件) | √ | × |
| 混淆矩阵无水印 | √ | × |
| 适用于的数据类型 | 一维、二维、三维 | 仅二维 |
| 最大迭代次数 | 不限制 | 10 |
| 导出预测结果、训练好的网络模型、神经网络训练相关参数(如loss值、准确度)等 | 可导出 | 不可导出 |
| CNN网络数据预处理、调参技巧视频教程 | √ | × |
五、获取公开版程序(需使用电脑浏览器打开)
CNNs分类公开版代码
注:公开版代码需使用MATLAB2022a及以上版本
六、获取完整版程序(使用电脑浏览器或者手机浏览器打开)
获取通道一(淘宝):点击此处获取完整版程序
获取通道二(本页面):点击下面“立即支付”按钮,付款后获取完整版代码下载链接和售后联系方式~本通道处于测试阶段,使用该通道可以额外优惠(仅需87元)。付款完成后刷新一下本页面即可看到下载链接。
(注意支付跳转失败的话,请使用浏览器打开本页面)
七、完整版代码重要更新
20230827 完成初版代码
八、常见问题
无。