使用LSTM/BiLSTM/GRU做模式识别(分类)
最后更新于:2024-04-07 21:37:08
一、程序介绍
-程序涵盖了LSTM/BiLSTM/GRU三种深度学习方法
-可以自由设置神经网络LSTM/BiLSTM/GRU Layer的层数和每层的隐藏单元数
-可以设置丢弃率
-可以快速划分训练集、验证集、测试集,程序运行完后绘制出测试集混淆矩阵
-可以设置自动纠正输入数据的行列方向
-支持向量和索引两种形式的标签输入
-多种训练参数可设置,包括求解器、迭代次数、初始学习率等等
-可设置随机种子,保证每次运行结果保持一致
–需要你做的基本只有导入数据和调参。
–绝大多数流程都被封装固化到函数中,仿照案例导入你的数据即刻得到结果~
二、代码运行环境
MATLAB2020a及更新版本。
三、程序具体内容
注: 图标代表该m文件为脚本文件,可以直接运行;
图标代表该m文件为脚本文件,可以直接运行; 图标代表函数文件,在没有输入变量的情况下无法直接运行。更详细的解释可以看这里。
图标代表函数文件,在没有输入变量的情况下无法直接运行。更详细的解释可以看这里。
1.scriptClassRNNs.m
使用MNIST数据集进行手写字体数字的识别的demo脚本文件,主要调用了FunClassRNNs函数。
2.FunClassRNNs.m
使用RNN衍生方法(包括GRU、LSTM、BiLSTM)进行模式识别(分类)的快速实现函数。
函数可调参数、相关设置以及输出参量如下:
[accuracy,recall,precision,net] = FunClassRNNs(dataX,dataY,divideR,rnnName,hiddenSizes,dropProb,auto,options,figflag)
% 使用RNN衍生方法(包括GRU、LSTM、BiLSTM)进行模式识别(分类)的快速实现函数
% 输入:
% dataX:输入数据,R*Q的矩阵,R为特征维度,Q为批次数,输入该变量时一定要注意行列方向是否正确
% dataY:标签值,可以为两种方式:
% 向量型:U*Q的矩阵,U为标签种类数,Q为批次数
% 索引型:1*Q的矩阵,Q为批次数
% divideR:数据集(训练集、验证集、测试集)划分比例,如:divideR =[0.6,0.2,0.2],
% 则代表60%数据用于训练集,20%数据用于验证集,20%数据用于测试集
% rnnName:使用的网络名称,可选项包括:’GRU’,’LSTM’,’BiLSTM’,注意大小写
% hiddenSizes:每个层(如LSTM层)的单元数,如果要设置多个层,则使用数组表示,数值一般在几十到几百之间
% 如第一层隐藏单元数为100,第二层隐藏单元数为60,则设置:hiddenSizes=[100,20]
% dropProb:丢弃层的丢弃概率,如果不丢弃,则设置为0,最大为1
% auto:是否进行自动纠错,’on’为是,否则为否。开启自动纠错后会智能调整训练、测试集的行列方向。
% options:一些与网络训练等相关的设置,使用结构体方式赋值,比如 options.MaxEpochs = 1000,具体包括:
% solverName:求解器,’sgdm’(默认) | ‘rmsprop’ | ‘adam’
% MaxEpochs:最大迭代次数,默认30
% MiniBatchSize:批尺寸,默认128
% GradientThreshold:梯度极限,默认为Inf
% InitialLearnRate:初始化学习速率(默认0.005)
% Plots:是否显示训练过程,’none’ 为不显示(默认) | ‘training-progress’为显示
% ValidationFrequency:验证频率,即每间隔多少次迭代进行一次验证,默认50
% LearnRateSchedule:即LearnRateSchedule是否在一定迭代次数后学习速率下降, LearnRateSchedule =’piecewise’为使用,’none’为不使用(默认)
% LearnRateDropPeriod:即LearnRateDropPeriod学习速率下降时的迭代数,默认为10
% LearnRateDropFactor:即LearnRateDropFactor学习速率下降因子,下降后变为LearnRateDropFactor*InitialLearnRate,LearnRateSchedule为0时可以赋0,默认为0.1
% (未启用)NorFlag:即Normalization Flag,设置为1时则在程序中进行数据归一化和反归一化操作,否则不进行,建议设置为1
% SeedFlag:随机种子标志,设置为1时启用随机种子,(默认为1)
% figflag:是否画图,’on’为画图,’off’为不画
% 输出:
% accuracy:测试集分类正确率
% recall: 召回率
% precision: 精确率
% net:训练好的网络
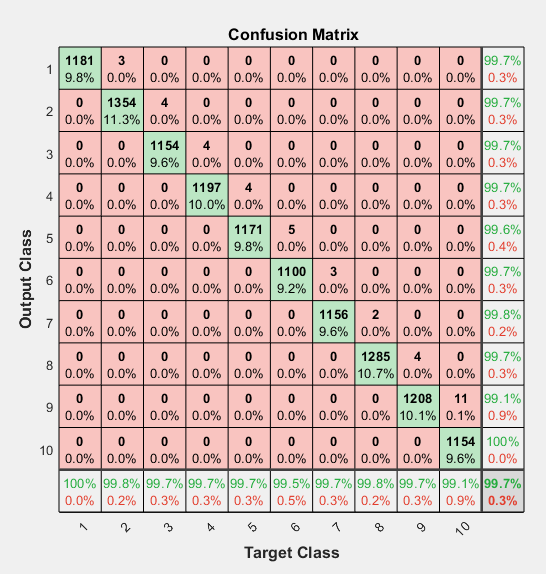
当figflag设置为‘on’时,将画出如下混淆矩阵图:
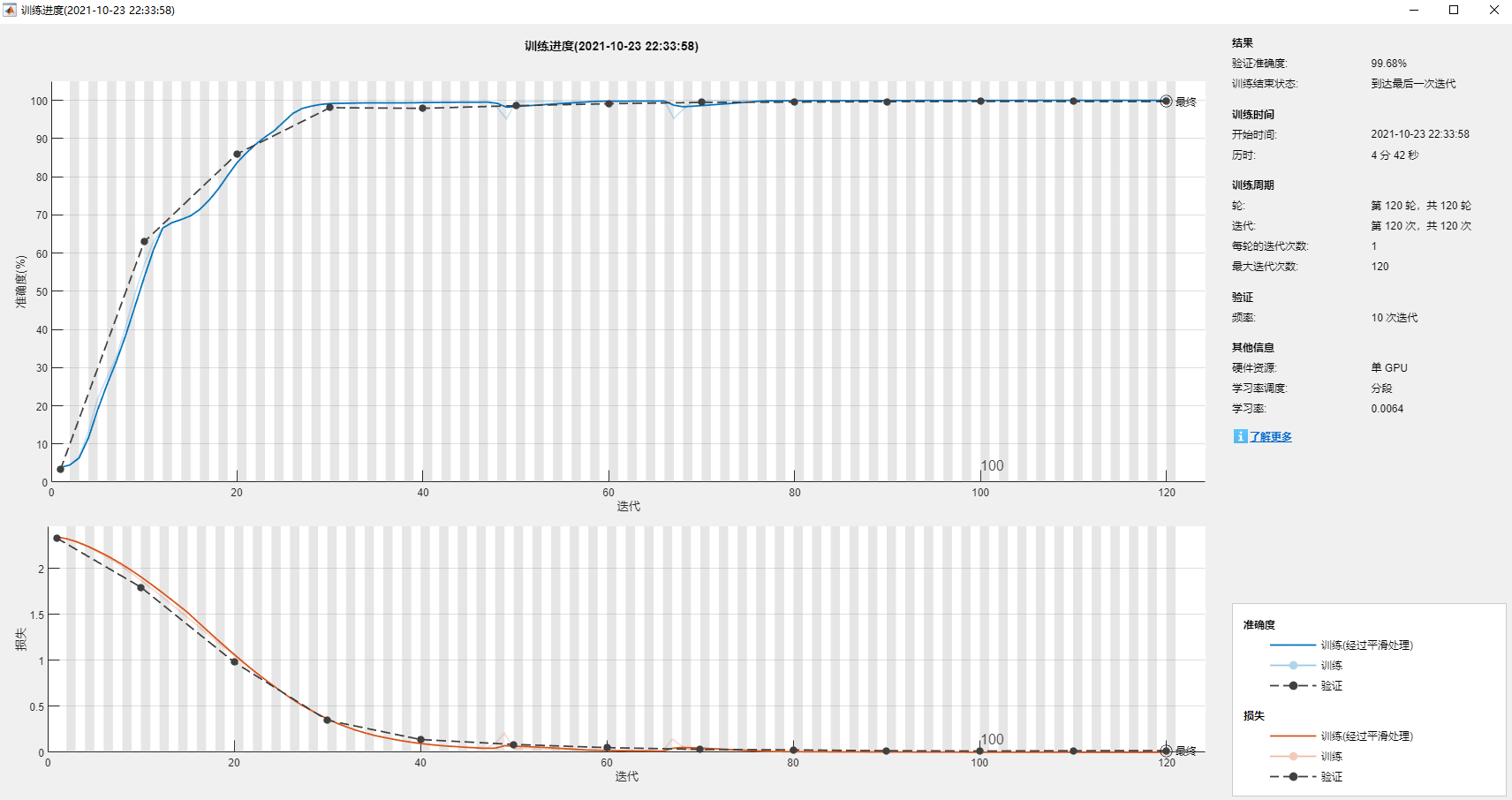
当Plots设置为 ‘training-progress’时,将画出如下训练过程图:
3.EvaluteClassResults.m
评估分类结果的函数文件,其中包括绘制混淆矩阵,计算召回率和精确率。函数参数如下:
[recall, precision] = EvaluteClassResults(outputs,targets,figflag)
% 对分类结果进行评价,包括:
% 画混淆矩阵图
% 计算 weigthed-Precision, weigthed-Recall和F1-score 参考 https://zhuanlan.zhihu.com/p/147663370?from_voters_page=true
% 输入:
% outputs:经过分类算法得到的分类结果,一维正整数
% targets:目标分类结果,一维正整数
% figflag:是否画图,’on’为画图,’off’为不画
% 输出:
% recall: 召回率
% precision: 精确率
4.clcEvaluteCalss
计算 召回率和精确率的底层函数。函数参数如下:
function [recall, precision] = clcEvaluteCalss(outputs,targets)
% 计算 weigthed-Precision, weigthed-Recall 参考 https://zhuanlan.zhihu.com/p/147663370?from_voters_page=true
% 注意,outputs和targets中的分类为整型,从1排序到n,不可跳数
四、快速开始
1.导入你的数据快速获取预测结果
根据你的文件类型的不同(excel,txt,csv等),将数据导入MATLAB的方法有所不同。同学们可以看博主针对常用文件的导入方法的这个教程。
需要注意你导入的数据需要满足FunClassRNNs函数对输入数据的要求,即:
输入数据:R*Q的矩阵,R为特征维度,Q为批次数,输入该变量时一定要注意行列方向是否正确
标签值:可以为两种方式:
– 向量型:U*Q的矩阵,U为标签种类数,Q为批次数
– 索引型:1*Q的矩阵,Q为批次数
2.实现分类
参照scriptClassRNNs文件中的函数调用方法编写自己的脚本文件。
五、获取程序(需使用电脑浏览器打开)
| 功能 | 正式版 | 公开版 |
| 数据导入、参数设置、模型训练与可视化结果展示 | √ | √ |
| 软件全部源码(函数m文件) | √ | × |
| 混淆矩阵无水印 | √ | × |
| 可使用’GRU’,’LSTM’,’BiLSTM’三类网络 | √ | 可使用’LSTM’ |
| 最大迭代次数 | 无限制 | 最大200 |
六、重要更新
20220517 现在可以导出神经网络训练过程的loss值和准确度
20211024 创建LSTM/BiLSTM/GRU做模式识别(分类)的初始版本代码