“类EMD”分解7合1画图工具(MATLAB)
最后更新于:2025-01-03 21:02:35
该代码合成了EMD,EEMD,CEEMD,CEEMDAN,ICEEMDAN,EWT,VMD这7种模态分解方法。
代码提供了不同模态分解方法的演示案例。
同学们需要做的基本只需要替换掉需要分解的数据即可,非常简单易用。
一、代码运行环境
MATLAB2020b及更新版本。
二、程序介绍
注: 图标代表该m文件为脚本文件,可以直接运行;
图标代表该m文件为脚本文件,可以直接运行; 图标代表函数文件,在没有输入变量的情况下无法直接运行。更详细的解释可以看这里。
图标代表函数文件,在没有输入变量的情况下无法直接运行。更详细的解释可以看这里。
1.demoEMDs.m文件
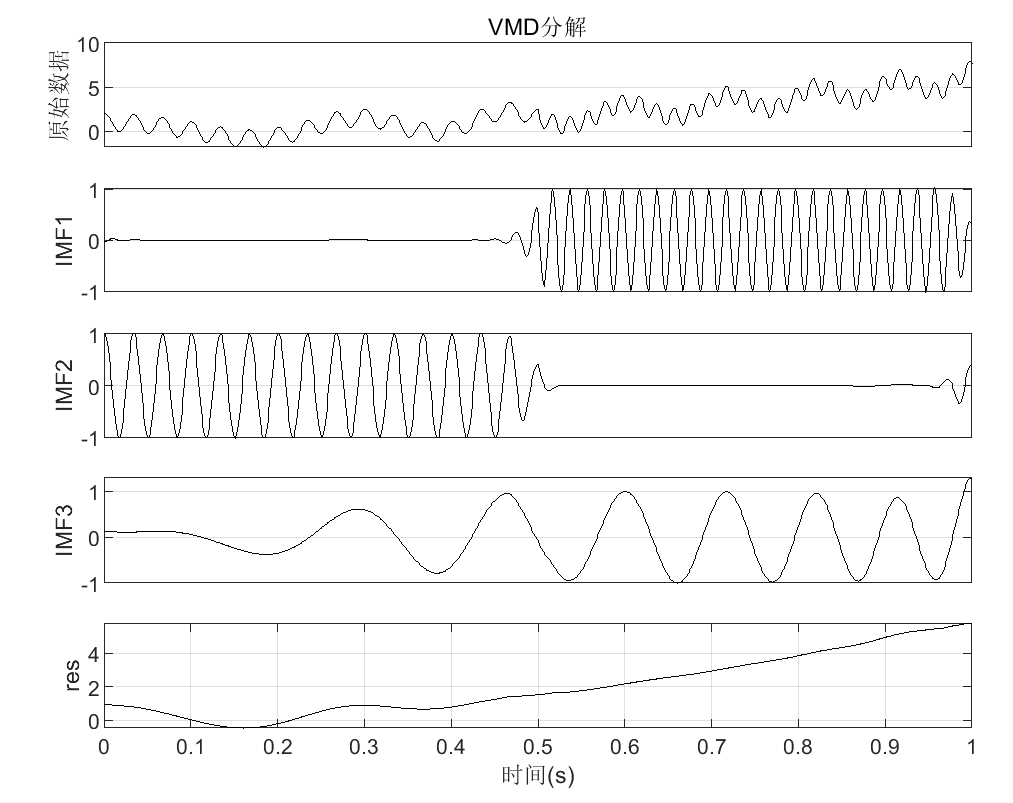
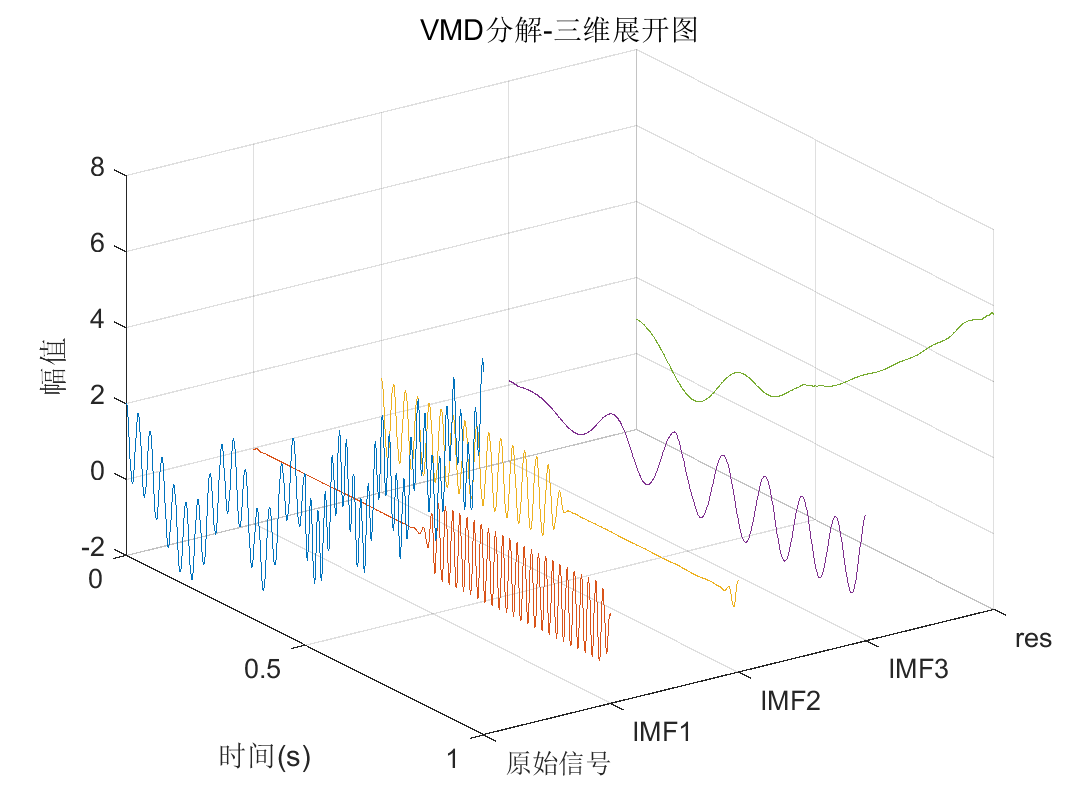
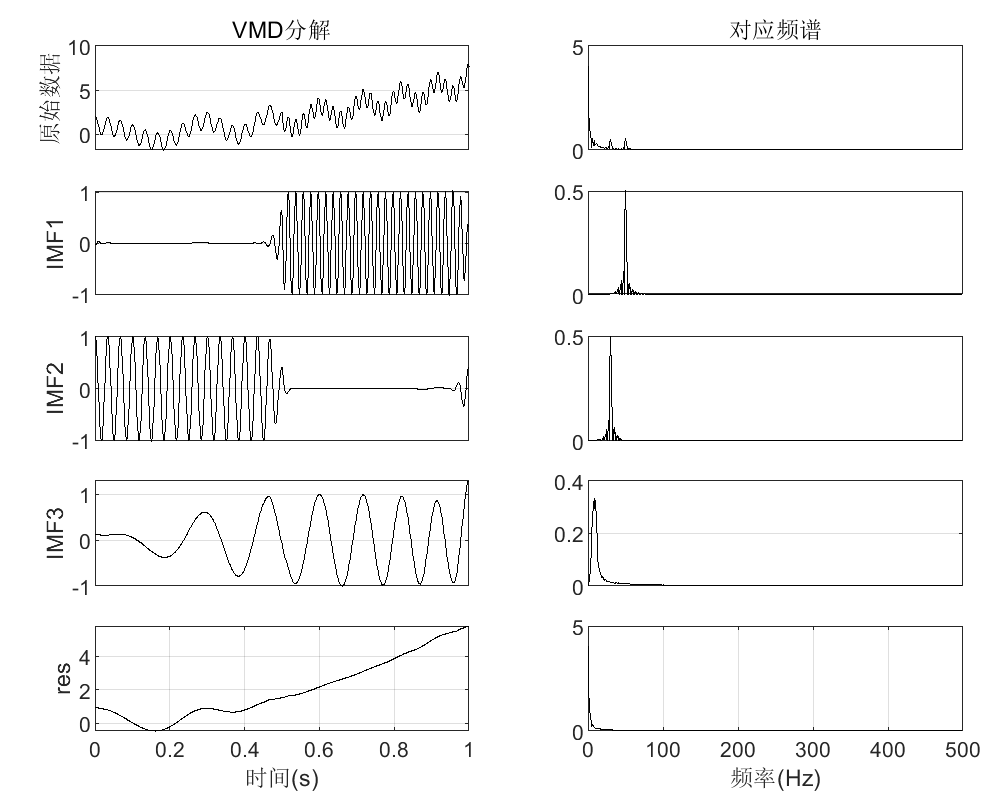
用于测试”类EMD”分解功能的脚本文件,可以直接运行,其中调用了pEMDs和pEMDsandFFT。其中演示了使用EMD、EEMD、CEEMD、CEEMDAN、ICEEMDAN、EWT和VMD等7种”类EMD”方法对输入信号进行分解,并绘制分解图(包括二维和三维)、重构误差图和分解结果及其频谱图。
运行该文件,将绘制以下图片(以VMD分解为例,实际每种分解方法都会绘制图片):
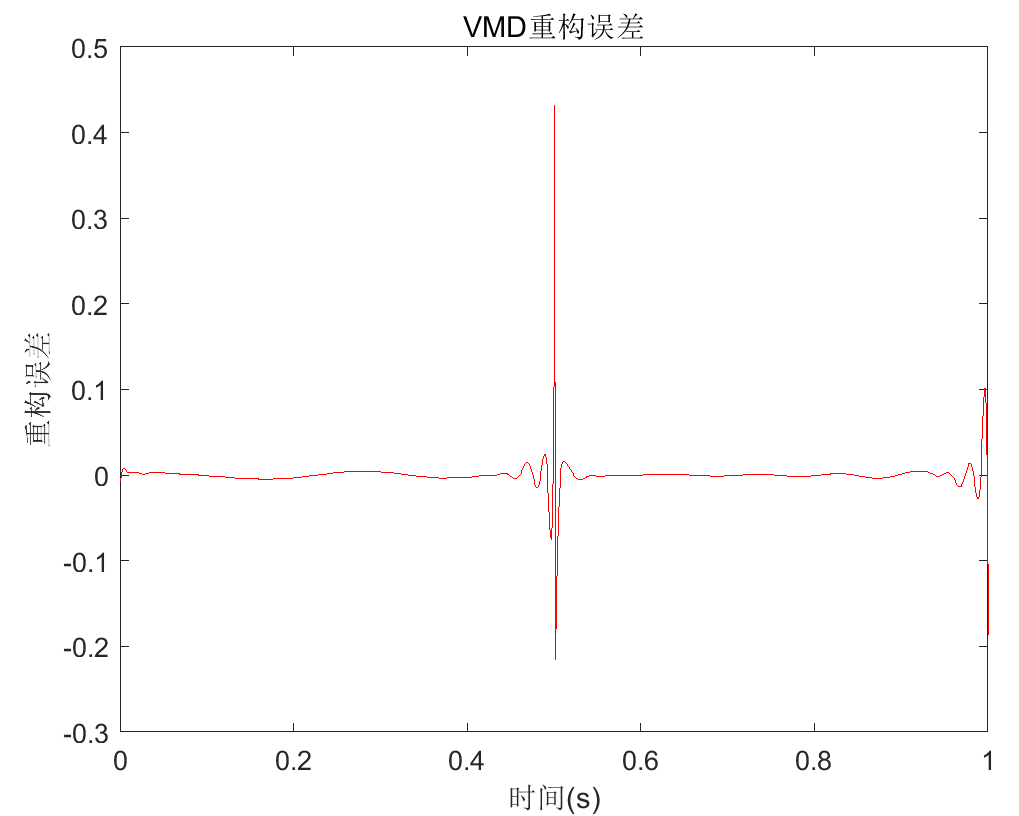
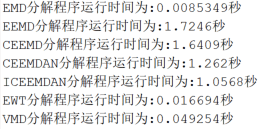
另外在命令行窗口将会打印各种算法的运行时间:
2.kEMDs.m文件
整合版”类EMD”分解函数,调用该函数会执行分解,不画图。该文件为函数文件,可以调用,不可以直接运行。该函数文件在pEMDs和pEMDsandFFT.m文件中调用。这个文件中实现了7种”类EMD”信号分解方法(EMD、EEMD、CEEMD、CEEMDAN、ICEEMDAN、EWT、VMD)的封装,属于偏底层的函数。
function [imf,CenFs,elapsedTime,reconError] = kEMDs(data,FsOrT,methodSel, options)
% 整合版"类EMD"分解函数,调用该函数会执行分解,不画图
% 目前可以实现的分解方法包括:
% EMD,EEMD,CEEMD,CEEMDAN,ICEEMDAN,EWT,VMD共7种
% 输入:
% data:待分解的数据(一维)
% FsOrT:采样频率或采样时间向量,如果为采样频率,该变量输入单个值;如果为时间向量,该变量为与y相同长度的一维向量。如果未知采样频率,可设置为1
% methodSel:选择分解方法,可以设置的选项包括:
% -'EMD'
% -'EEMD'
% -'CEEMD'
% -'CEEMDAN'
% -'ICEEMDAN'
% -'EWT'
% -'VMD'
% options:其他可设置的参数,使用结构体形式幅值,对于不同分解方法,需要设置的参数有所不同
% - options.Nstd 为附加噪声标准差与Y标准差之比,默认为0.2
% - options.NE 为对信号的平均次数,默认为100
% - options.MaxIter:最大迭代次数,默认为1000
% - options.MaxNumIMFs 最大的IMF数量,在EMD和EWT中可选设置,默认为缺省
% - options.alpha 惩罚因子,在VMD中设置,默认值为2000
% - options.K 指定分解模态数,仅在VMD中可设置
% - options.tol 收敛容差,在VMD中设置,是优化的停止准则之一,可以取 1e-6~5e-6
% 输出:
% imf:内涵模态分量,统一为n*m格式,其中n为模态数,m为数据点数。例如 imf(1,:)即IMF1,imf(end,:)即为残差
% 注意,调用该函数得到的imf,其排列均是从高频向低频排列,这也是为了方便大家研究使用而保持了统一
% CenFs:即CentralFrequencies,各imf分量的中心频率,仅VMD分解可以输出,使用其他分解方法,该变量输出0
% elapsedTime:程序运行时间,单位为秒
% reconError:重构误差,即原始信号与重构信号之间的均方根误差
% 注意:在使用该代码之前,请务必安装工具箱:https://khsci.com/docs/index.php/2020/04/09/1/
% 代码说明:https://khsci.com/docs/index.php/2024/06/27/emds/
% 更多说明:https://zhuanlan.zhihu.com/p/704773627/3.pEMDs.m文件
整合版”类EMD”分解函数,调用该函数将会分解并画图(模态分解图,无频谱),会绘制重构误差图。该文件为函数文件,可以调用,不能直接运行。
function [imf,CenFs,elapsedTime,reconError] = pEMDs(data,FsOrT,methodSel, options)
% 整合版"类EMD"分解函数,调用该函数将会分解并画图(模态分解图,无频谱),会绘制重构误差图
% 目前可以实现的分解方法包括:
% EMD,EEMD,CEEMD,CEEMDAN,ICEEMDAN,EWT,VMD共7种
% 输入:
% data:待分解的数据(一维)
% FsOrT:采样频率或采样时间向量,如果为采样频率,该变量输入单个值;如果为时间向量,该变量为与y相同长度的一维向量。如果未知采样频率,可设置为1
% methodSel:选择分解方法,可以设置的选项包括:
% -'EMD'
% -'EEMD'
% -'CEEMD'
% -'CEEMDAN'
% -'ICEEMDAN'
% -'EWT'
% -'VMD'
% options:其他可设置的参数,使用结构体形式幅值,对于不同分解方法,需要设置的参数有所不同
% - options.Nstd 为附加噪声标准差与Y标准差之比,默认为0.2
% - options.NE 为对信号的平均次数,默认为100
% - options.MaxIter:最大迭代次数,默认为1000
% - options.MaxNumIMFs 最大的IMF数量,在EMD和EWT中可选设置,默认为缺省
% - options.alpha 惩罚因子,在VMD中设置,默认值为2000
% - options.K 指定分解模态数,仅在VMD中可设置
% - options.tol 收敛容差,在VMD中设置,是优化的停止准则之一,可以取 1e-6~5e-6
% 输出:
% imf:内涵模态分量,统一为n*m格式,其中n为模态数,m为数据点数。例如 imf(1,:)即IMF1,imf(end,:)即为残差
% 注意,调用该函数得到的imf,其排列均是从高频向低频排列,这也是为了方便大家研究使用而保持了统一
% CenFs:即CentralFrequencies,各imf分量的中心频率,仅VMD分解可以输出
% elapsedTime:程序运行时间,单位为秒
% reconError:重构误差,即原始信号与重构信号之间的均方根误差
% 代码说明:https://khsci.com/docs/index.php/2024/06/27/emds/
% 更多说明:https://zhuanlan.zhihu.com/p/704773627/
% 注意:在使用该代码之前,请务必安装工具箱:https://khsci.com/docs/index.php/2020/04/09/1/4.pEMDsandFFT.m文件
绘制信号模态分解与各IMF分量频谱对照图,也会绘制重构误差图。该文件为函数文件,可以调用,不能直接运行。
function [imf,CenFs,elapsedTime,reconError] = pEMDsandFFT(data,FsOrT,methodSel, options)
% 画信号模态分解与各IMF分量频谱对照图,会绘制重构误差图
% 目前可以实现的分解方法包括:
% EMD,EEMD,CEEMD,CEEMDAN,ICEEMDAN,EWT,VMD共7种
% 输入:
% data:待分解的数据(一维)
% FsOrT:采样频率或采样时间向量,如果为采样频率,该变量输入单个值;如果为时间向量,该变量为与y相同长度的一维向量。如果未知采样频率,可设置为1
% methodSel:选择分解方法,可以设置的选项包括:
% -'EMD'
% -'EEMD'
% -'CEEMD'
% -'CEEMDAN'
% -'ICEEMDAN'
% -'EWT'
% -'VMD'
% options:其他可设置的参数,使用结构体形式幅值,对于不同分解方法,需要设置的参数有所不同
% - options.Nstd 为附加噪声标准差与Y标准差之比,默认为0.2
% - options.NE 为对信号的平均次数,默认为100
% - options.MaxIter:最大迭代次数,默认为1000
% - options.MaxNumIMFs 最大的IMF数量,在EMD和EWT中可选设置,默认为缺省
% - options.alpha 惩罚因子,在VMD中设置,默认值为2000
% - options.K 指定分解模态数,仅在VMD中可设置
% - options.tol 收敛容差,在VMD中设置,是优化的停止准则之一,可以取 1e-6~5e-6
% 输出:
% imf:内涵模态分量,统一为n*m格式,其中n为模态数,m为数据点数。例如 imf(1,:)即IMF1,imf(end,:)即为残差
% 注意,调用该函数得到的imf,其排列均是从高频向低频排列,这也是为了方便大家研究使用而保持了统一
% CenFs:即CentralFrequencies,各imf分量的中心频率,仅VMD分解可以输出
% elapsedTime:程序运行时间,单位为秒
% reconError:重构误差,即原始信号与重构信号之间的均方根误差
% 代码说明:https://khsci.com/docs/index.php/2024/06/27/emds/
% 更多说明:https://zhuanlan.zhihu.com/p/704773627/
% 注意:在使用该代码之前,请务必安装工具箱:https://khsci.com/docs/index.php/2020/04/09/1/
4.pFFT.m文件
封装好的fft计算程序,在pEMDsandFFT中调用,一般不需要修改。
三、快速开始
0.安装工具箱
点击这个链接,按照网页中的说明安装TFA_Toolboxs工具箱,这个工具箱中有模态分解需要用到的第三方库函数。
1.运行测试脚本
先在MATLAB里打开下载好的文件夹,然后运行demoEMDs.m程序,程序运行完毕后如果没报错,且正常画出分解图像,则说明运行环境正常,程序正确。
2.修改仿真数据/导入数据
复制一个demoEMDs.m的文件副本,在这个副本里做如下修改:
(1)第一种情况,你可能想要对你自己要研究的仿真数据进行模态分解测试,此时你需要对 demoEMDs.m 脚本文件中的第1小节内容进行修改替换即可。需要注意的是,请最好保持变量名的一致,即将待分解信号命名为data,采样频率或者时间轴命名为FsOrT。此时数据替换完成。
(2)第二种情况,你可能是想对一段真实采集的数据进行模态分解,此时需要根据你的文件类型的不同(excel,txt,csv等),将数据导入MATLAB的方法有所不同。同学们可以看博主针对常用文件的导入方法的这个教程,教程上未包含的数据类型,大家可以再参考这个文档。导入完成后请将这个待分解信号命名为data。
3.保留你需要的分解方法,并设置参数
demoEMDs.m中演示了七种方法的分解案例,你可以删掉不需要的分解方法,只保留你需要的部分即可。而相关参数设置,大家可以参照案例中的写法设置。
上述替换过程大家有不清楚的,请参考视频。
4.运行程序
此时运行程序即可。
四、关于完整版与公开版代码
| 功能 | 完整版 | 公开版 |
| 绘制类EMD分解图、绘制类EMD分解图及其频谱图、重构误差图 | √ | √ |
| 软件全部源码(函数m文件) | √ | × |
| 可导出分解结果imf、中心频率、重构误差值 | √ | × |
| 可分析数据长度 | 无限制 | 1000个点以内 |
五、获取公开版程序(需使用电脑浏览器打开)
“类EMD”分解7合1画图公开版代码V2
注:公开版代码需使用MATLAB2022a及以上版本。
六、获取完整版程序(使用电脑浏览器或者手机浏览器打开)
获取通道一(淘宝):点击此处获取完整版程序
获取通道二(本页面):点击下面“立即支付”按钮,付款后获取完整版代码下载链接和售后联系方式~本通道处于测试阶段,使用该通道可以额外优惠(仅需91元)。付款完成后刷新一下本页面即可看到下载链接。
(注意支付跳转失败的话,请使用浏览器打开本页面)
七、完整版代码重要更新
20240629 完成初版代码
八、常见问题
问题1:分解出来的各分量没有按照从高频到低频的顺序排列,或者有些信号分解后从高频到低频排列,有些从低频到高频排列。
回答1:这是由于MATLAB版本在2020a以下,程序调用了第三方的vmd函数,该函数在求出imf分量时频率排序不稳定。安装MATLAB2020a及以上版本可以解决该问题,实现imf分量频率从高频到低频的顺序排列。
问题2:VMD中参数K和分解出来的数量是什么关系?
回答2:K的值等于IMF数量加1,也就是如果设置K=4,则会分解出3个IMF分量和1个趋势项res。
问题3:VMD中K的数值应该怎样选取?
回答3:对于K的取值,可以通过一些评价指标来进行评估,综合研判取值。比如使用中心频率判断、使用相关系数判断、使用峭度值判断等,不过没有放之四海而皆准的方法。在使用VMD算法进行信号分解时,需要综合考虑信号的特性、应用需求和实际效果等因素,来确定k的取值,最简单的方法就是参考研究领域相关论文的常用方法。
当然,如果你有选择困难症,也可以直接用店铺中的VMD优化算法,可以直接计算得到最优的K值(还有alpha值):点击这里获取。
问题4:除了VMD,其他分解方法可以设置分解得到的imf的数量吗?
在网站现有的“类EMD”分解方法中,只有VMD分解是可以指定imf数的,其他的分解方法的分解数量均是自适应的,无法指定。
问题5:参数NE、Nstd、MaxIter该怎么设置?
NE: 噪声系数的数量。这是一个整数,代表生成噪声实例的次数。增加NE可以改善结果的一致性,但会增加计算时间。一般来说,NE的设置可以在50到100之间,具体可以根据你的数据和计算能力进行调整。
Nstd: 噪声标准差。这是一个浮点数,它定义了添加到信号中的噪声的标准偏差。通常,Nstd的值设置在0.1到0.2之间,它会影响到信号分解的精度。设置过高可能会引入太多噪声,过低则可能对噪声的效果不够。
MaxIter: 最大迭代次数。这是在执行经验模式分解过程中,每个模式(IMF)最大允许的迭代次数。如果迭代次数过少,可能无法得到一个好的IMF,如果过多,可能会导致计算时间过长。一般情况下,MaxIter的值可以设置在100到1000之间,具体取决于你的数据的复杂性和计算能力。