SVM多分类算法 – 基于支持向量机的多类别分类【MATLAB】
最后更新于:2025-10-12 00:14:46
一、代码运行环境
- MATLAB: 理论上MATLAB2016以上可以使用,推荐使用MATLAB2024a及更新版本。
二、程序介绍
程序文件结构
SVM_Multiclass_Classification/
├── demoSVMMultiClass.m # 演示脚本
├── FunSVMMultiClass.m # 核心函数
├── iris.csv # 鸢尾花数据集
├── 代码说明.txt # 代码说明文档
└── figure/ # 结果图片文件夹
├── 图1_混淆矩阵.png
├── 图2_分类对比.png
├── 图3_性能指标.png
└── 图4_数据分布.png文件说明
1. demoSVMMultiClass.m
- 说明:SVM多分类算法的演示脚本文件,是核心函数
FunSVMMultiClass的测试文件,可以直接运行。 - 功能:加载鸢尾花数据集,设置算法参数,调用核心函数进行多分类训练和测试,输出性能指标并生成可视化结果。
- 运行结果:
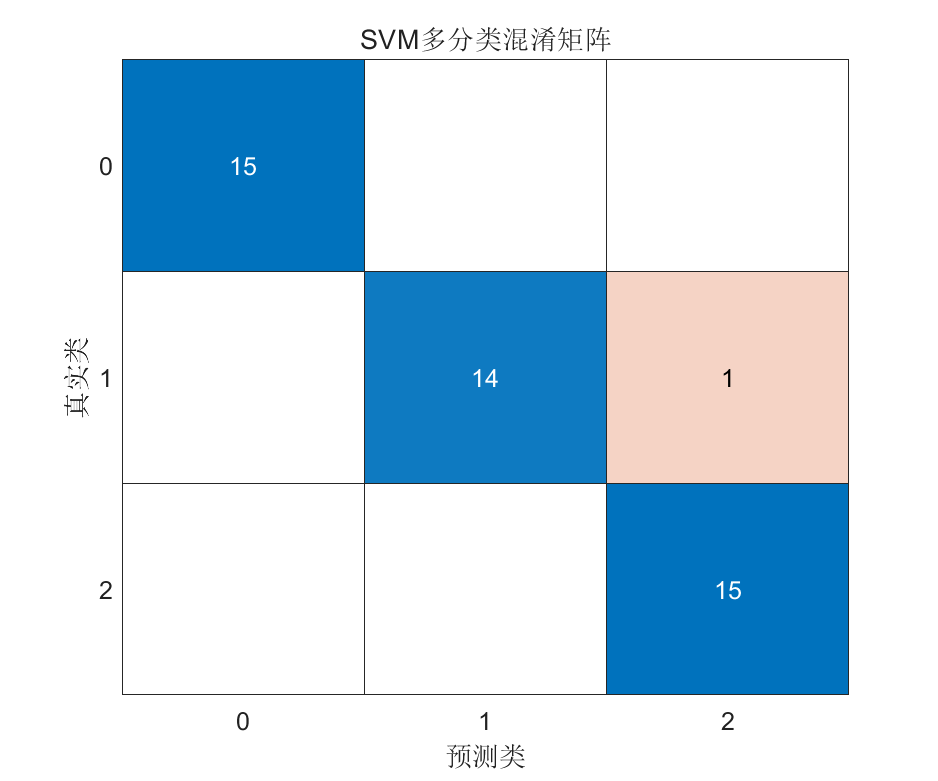
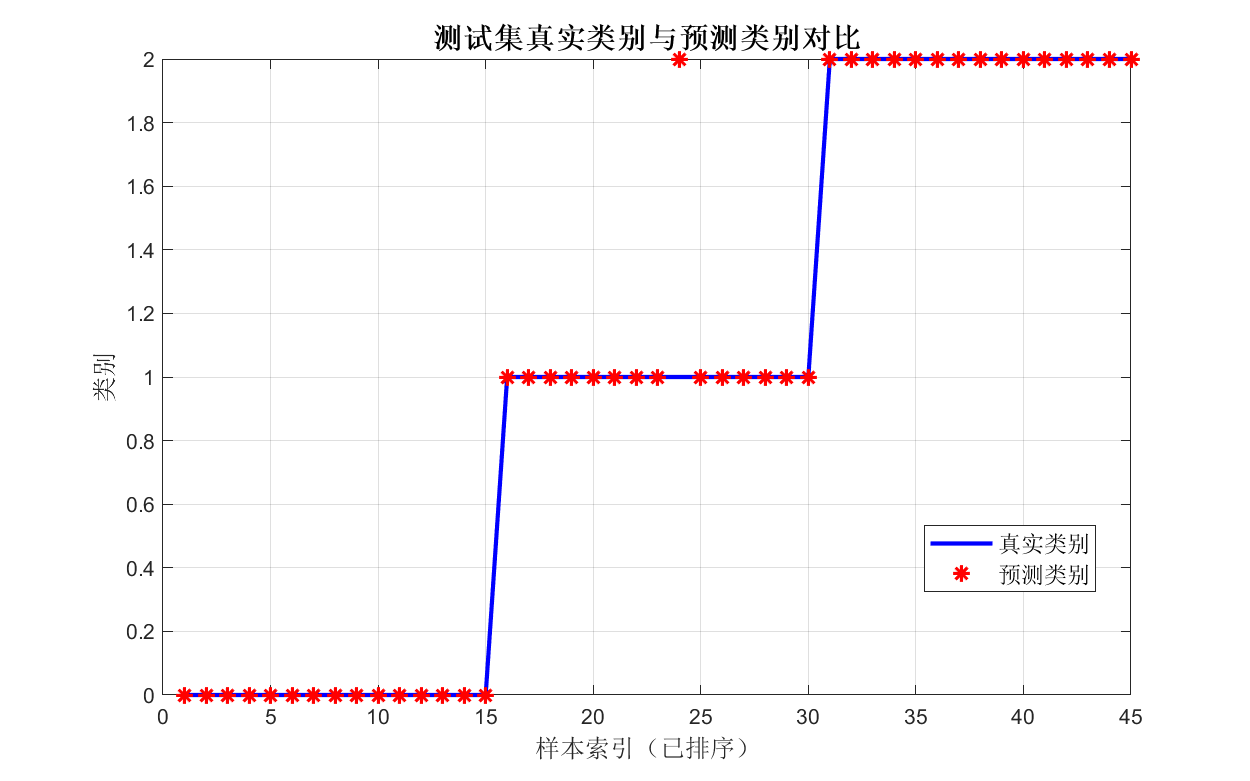
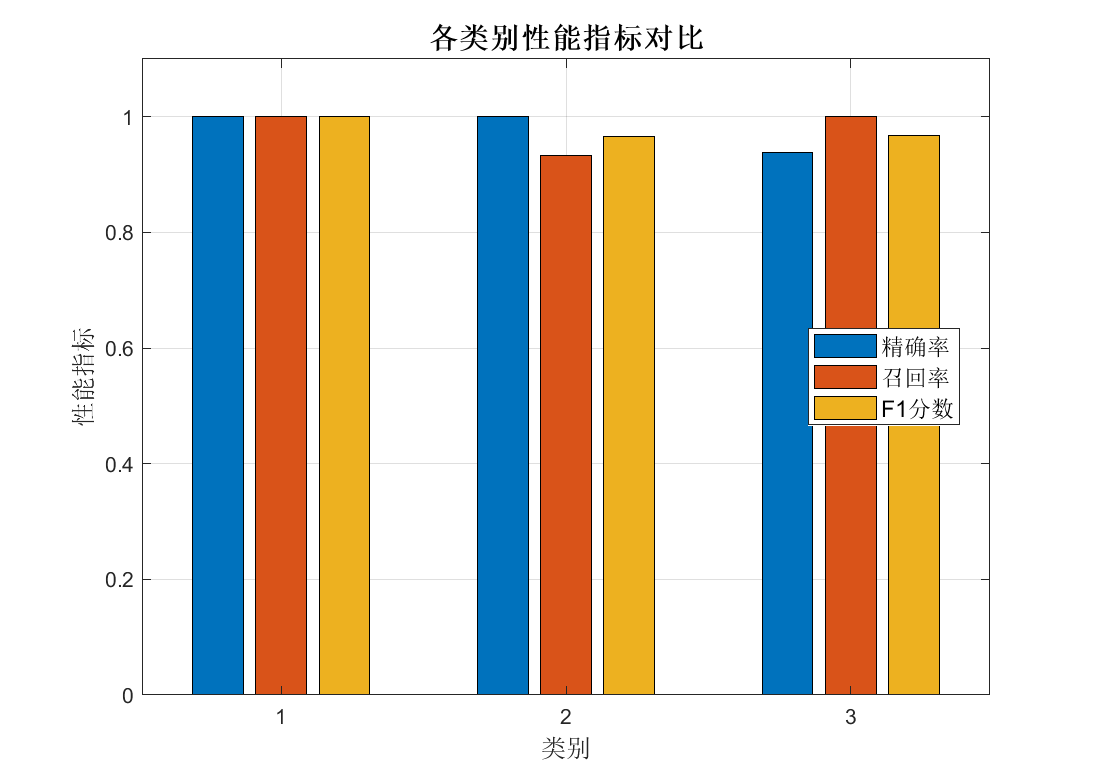
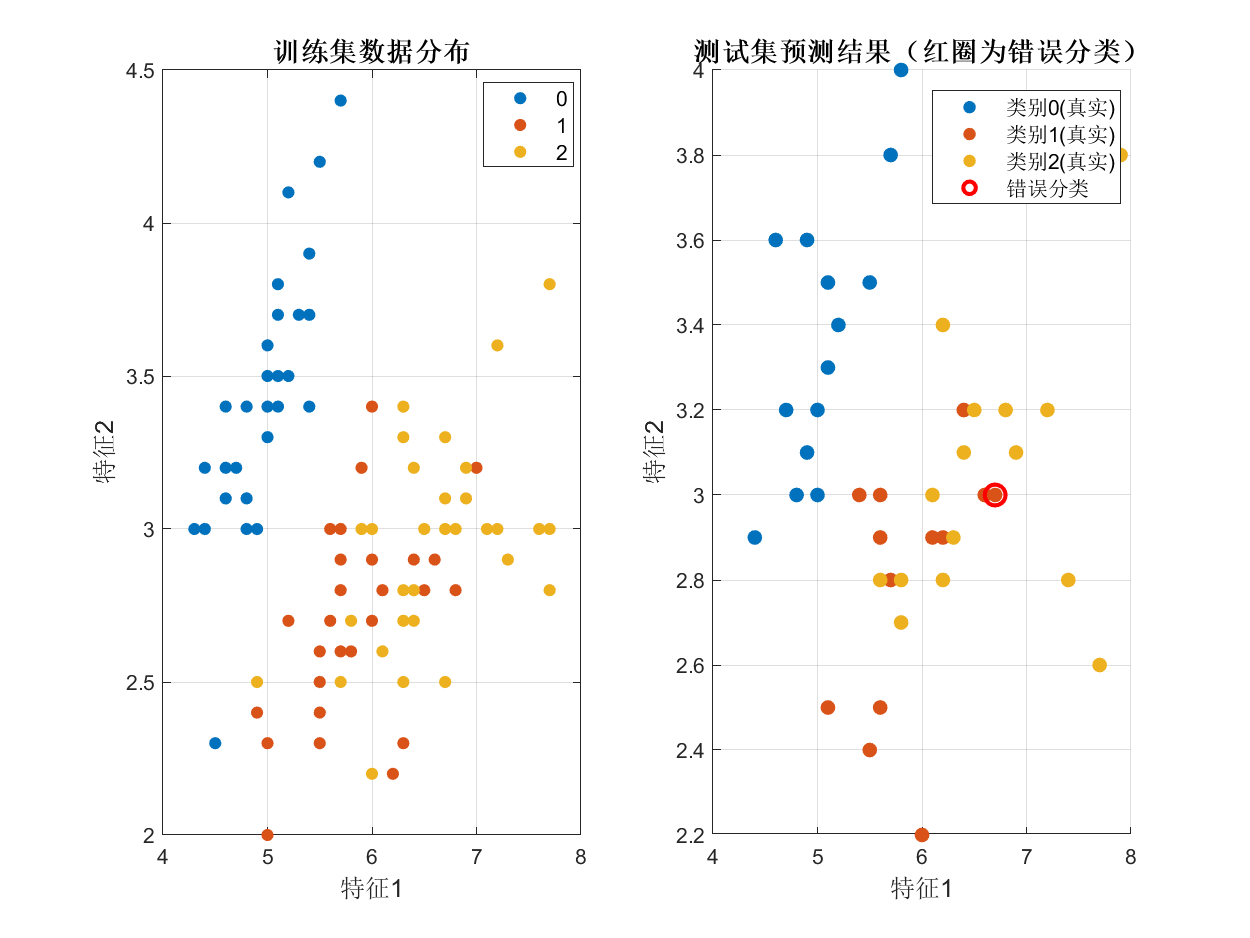
命令行输出示例:
数据加载完成!
数据集大小:150个样本,4个特征
===== SVM多分类算法 =====
训练集样本数: 105
测试集样本数: 45
类别数量: 3
===== 分类结果 =====
测试集准确率: 100.00%
精确率: 100.00%
召回率: 100.00%
F1分数: 100.00%
各类别性能指标:
类别 0: 精确率=100.00%, 召回率=100.00%, F1=100.00%
类别 1: 精确率=100.00%, 召回率=100.00%, F1=100.00%
类别 2: 精确率=100.00%, 召回率=100.00%, F1=100.00%
所有图片已保存到figure文件夹
演示完成!2. FunSVMMultiClass.m
- 说明:SVM多分类算法的核心函数,实现了完整的多类别分类流程。
- 功能:
- 支持多种核函数(线性核、RBF核、多项式核)
- 采用One-vs-Rest(OvR)策略进行多分类
- 自动数据标准化和训练集/测试集划分
- 完整的性能评估(准确率、精确率、召回率、F1分数)
- 生成5种可视化结果(混淆矩阵、分类对比、性能指标、数据分布、决策边界)
- 所有图片自动保存到figure文件夹
- 函数定义及参数解释:
function [accuracy, recall, precision, F1, SVMModels, info] = FunSVMMultiClass(dataX, dataY, options)
% SVM多分类算法 - 使用One-vs-Rest策略进行多类别分类
%
% 输入参数:
% dataX - 输入特征数据,N×M的矩阵,N为样本数,M为特征数
% dataY - 标签数据,N×1的向量,N为样本数
% options - 参数设置结构体,包含以下字段:
% divideRatio:训练集比例,默认0.7(70%训练,30%测试)
% kernelFunction:核函数类型,'linear'|'rbf'|'polynomial',默认'rbf'
% kernelScale:核尺度参数,默认'auto'
% boxConstraint:箱式约束(惩罚系数),默认1
% polynomialOrder:多项式核函数阶数,默认3
% standardize:是否标准化数据,true|false,默认true
% figflag:是否绘图,'on'|'off',默认'on'
% randomSeed:随机种子,默认123456
%
% 输出参数:
% accuracy - 测试集分类准确率
% recall - 召回率(各类别平均)
% precision - 精确率(各类别平均)
% F1 - F1分数(各类别平均)
% SVMModels - 训练好的SVM模型集合
% info - 包含训练数据、测试数据、预测结果等详细信息的结构体3. iris.csv
- 说明:经典的鸢尾花数据集,包含150个样本,4个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度),3个类别(Setosa、Versicolor、Virginica)。
- 用途:作为演示数据,展示SVM多分类算法的效果。
4. 代码说明.txt
- 说明:详细的代码使用说明文档,包含环境要求、快速开始指南、主要功能介绍和参数说明。
三、快速开始
1. 运行测试脚本
步骤:
1. 在MATLAB中打开下载好的 SVM_Multiclass_Classification 文件夹 2. 确保当前路径为该文件夹的根目录 3. 在命令行窗口输入并运行:
demoSVMMultiClass4. 程序运行完毕后,如果没有报错且正常绘制4张图像,则说明运行环境正常
判断程序是否正常运行:
- 命令行窗口输出完整的性能指标信息
- 自动弹出4个图形窗口,显示混淆矩阵、分类对比、性能指标和数据分布
- figure文件夹中自动生成4张PNG图片
2. 修改仿真数据/导入数据
情况一:使用自己的仿真数据
1. 复制一个 demoSVMMultiClass.m 的文件副本(如 myDemo.m) 2. 在副本中修改数据导入部分(第9-15行):
%% 1. 数据导入
% 使用自己的数据替换
X = your_feature_data; % 替换为你的特征数据矩阵(N×M)
Y = your_label_data; % 替换为你的标签向量(N×1)注意事项:
X必须是数值型矩阵,每行为一个样本,每列为一个特征Y必须是向量,可以是数值型或categorical类型- 样本数N必须与标签数量一致
- 特征数M建议在2-100之间,过多的特征可能需要特征选择或降维
情况二:使用真实采集的数据
从Excel文件导入:
% 方法1:使用readtable(推荐)
data = readtable('your_data.xlsx');
X = data{:, 1:end-1}; % 前面的列为特征
Y = data{:, end}; % 最后一列为标签
% 方法2:使用xlsread
[num, txt, raw] = xlsread('your_data.xlsx');
X = num(:, 1:end-1);
Y = num(:, end);从CSV文件导入:
data = readtable('your_data.csv');
X = data{:, 1:end-1};
Y = data{:, end};从TXT文件导入:
% 假设数据为空格或Tab分隔
data = load('your_data.txt');
X = data(:, 1:end-1);
Y = data(:, end);如果没有测试标签: 如果你的数据没有分开的测试集标签,需要修改代码:
1. 删除或注释掉性能评估相关代码 2. 只关注模型训练和预测结果
3. 调整算法参数(可选)
在 demoSVMMultiClass.m 的第21-29行可以调整算法参数:
% 核函数选择
options.kernelFunction = 'rbf'; % 'linear':线性核,适合线性可分问题
% 'rbf':径向基核,适合大部分非线性问题(推荐)
% 'polynomial':多项式核,适合特定非线性问题
% 数据划分比例
options.divideRatio = 0.7; % 0.7表示70%训练,30%测试
% 可调整为0.6-0.8之间
% 惩罚系数(C参数)
options.boxConstraint = 1; % 值越大,对误分类的惩罚越大
% 建议范围:0.1-100
% 核尺度参数(gamma参数)
options.kernelScale = 'auto'; % 'auto':自动选择最优值(推荐)
% 也可设置为具体数值,如0.1、1、10等
% 多项式核阶数(仅polynomial核函数需要)
options.polynomialOrder = 3; % 建议范围:2-5
% 是否标准化数据
options.standardize = true; % true:标准化(推荐),false:不标准化
% 是否绘图
options.figflag = 'on'; % 'on':绘制图形,'off':不绘图
% 随机种子
options.randomSeed = 123456; % 设置固定值可保证结果可重复参数调优建议:
1. 首先使用默认参数运行,观察结果 2. 如果准确率不理想,尝试调整核函数类型 3. 调整惩罚系数 boxConstraint,通常在[0.1, 1, 10, 100]中选择 4. 如果使用RBF核,可以尝试不同的 kernelScale 值
4. 运行程序
完成以上修改后,在MATLAB命令行窗口运行:
myDemo % 或者你修改后的脚本名称程序会自动完成数据加载、模型训练、预测和可视化等所有步骤。
四、关于完整版与公开版代码
> 代码分为完整版和公开版(试用版),以满足不同用户的需求。
| 功能 | 完整版 | 公开版 |
| 数据导入、参数设置 | √ | √ |
| 软件全部源码 | √ | × |
| 核心函数源码 | 完整可见 | 加密(.p文件) |
| 数据样本数限制 | 无限制 | 最大100个样本 |
| 所有核函数支持 | √ | √ |
| 完整可视化功能 | √ | √ |
| 画图水印 | 无水印 | 有水印标识 |
| 视频教程 | √ | × |
| 技术支持 | 提供技术支持 | 无技术支持 |
| 代码注释 | 详细注释 | 部分注释 |
📥 五、获取公开版程序
SVM_Multiclass_MATLAB_试用版_V25wp9x4s
注:公开版代码需使用MATLAB2022a及以上版本。
💎 六、获取完整版程序
点击下面”立即支付“按钮,付款后获取完整版代码下载链接和售后联系方式~付款完成后刷新一下本页面即可看到下载链接。
(注意:支付跳转失败的话,请使用浏览器打开本页面)
七、完整版代码重要更新
- 2025-01-10: 完成初版代码
- 实现基于SVM的多分类算法
- 支持多种核函数(线性、RBF、多项式)
- 实现One-vs-Rest多分类策略
- 提供完整的性能评估指标
- 生成5种可视化结果
- 自动保存图片到figure文件夹
八、常见问题
Q1: 运行程序时提示找不到文件?
A: 请确保:
1. 当前MATLAB工作路径为 SVM_Multiclass_Classification 文件夹 2. 所有文件(demoSVMMultiClass.m、FunSVMMultiClass.m、iris.csv)都在同一目录下
Q2: 图片无法正常显示或保存?
A:
1. 检查是否有创建 figure 文件夹的权限 2. 尝试手动创建 figure 文件夹 3. 检查 options.figflag 是否设置为 'on'
Q3: 准确率很低怎么办?
A: 可以尝试:
1. 更换核函数类型(尝试 ‘linear’、’rbf’、’polynomial’) 2. 调整惩罚系数 options.boxConstraint(尝试0.1、1、10、100) 3. 确保数据已标准化(options.standardize = true) 4. 增加训练集比例(如 options.divideRatio = 0.8) 5. 检查数据质量和标签是否正确
Q4: 如何保存训练好的模型?
A: 在程序运行后,使用MATLAB的 save 命令:
save('my_svm_models.mat', 'SVMModels', 'info');加载模型:
load('my_svm_models.mat');Q5: 如何用训练好的模型预测新数据?
A: 使用返回的 SVMModels 和 info 结构体:
% 假设 newData 是新的特征数据
if info.standardize
newData_std = (newData - info.mu) ./ info.sigma; % 使用训练时的均值和标准差
else
newData_std = newData;
end
% 预测
predictions = predict(SVMModels, newData_std);Q6: 程序运行时间过长?
A:
1. 减少样本数量 2. 减少特征维度(使用PCA等降维方法) 3. 使用线性核函数(速度最快) 4. 调小 boxConstraint 值
Q7: 如何引用本代码?
A: 如果在论文或报告中使用了本代码,建议注明:
代码来源:Mr.看海,SVM多分类算法MATLAB实现
网站:www.khsci.com/docs—
*如有其他问题,欢迎访问 www.khsci.com/docs 获取更多帮助信息。*